La lettera contro la "superintelligenza AI" è la soluzione sbagliata a un problema giusto solo a metà
L'idea di prevenire rischi è ammirevole, ma l'esecuzione no.

Chiediamo una proibizione allo sviluppo della superintelligenza, finché
- non ci sia ampio consenso dalla comunità scientifica che si possa fare in modo sicuro e controllabile e
- ampio supporto pubblico

Questo è il – volutamente breve – testo della lettera aperta sulla superintelligenza firmata da moltissimi personaggi illustri:
il premio Nobel Geoffrey Hinton e Yoshua Bengio, due ricercatori veterani del settore AI,
Susan Rice, National Security Advisor nella presidenza Obama,
Mark Beall, ex direttore di AI Strategy per il Dipartimento della Difesa USA (vi ricordate quello che Trump vorrebbe chiamare Ministero della guerra?)...
Ci sono anche un paio di italiani notevoli: il nostro europarlamentare Brando Benifei, relatore dell'AI Act, e padre Paolo Benanti, consigliere di papa Francesco sull'AI, membro del New Artificial Intelligence Advisory Board dell'ONU e presidente della Commissione Algoritmi del Dipartimento per l'informazione e l'editoria del governo.
E ancora: il principe Harry e Meghan, Steve Bannon, l'ex stratega di Trump, il filosofo Peter Singer, will.i.am (– a-a-ai gotta feeling 🎶), Yuval Noah Harari, Tristan Harris (technology ethicist, ex Google, che appare in The Social Dilemma) e moltissime altre persone.
La varietà dei firmatari è ammirevole: ci sono figure competenti e con posizioni condivisibili, ma anche qualche cialtrone tipo Harari.
Questa varietà temo però sia sintomo di un problema della lettera, e dunque eccoci:
i probbblemi della lettera
1- ma cosa è la superintelligenza

nel context prima della lettera vera e propria si dice
"superintelligence in the coming decade that can significantly outperform all humans on essentially all cognitive tasks"
Con superintelligenza si intende qualcosa che è oltre l'intelligenza artificiale generale che ci è stata dondolata davanti negli ultimi anni: l'AGI sarebbe un sistema AI con le capacità cognitive pari a quelle di un umano in tutto e per tutto.
La superintelligenza, invece, dovrebbe essere un sistema in grado di superare cognitivamente qualsiasi umano.
Questa prospettiva fa paura,
è intuitivo capire il perché: costruiamo oggetti e sistemi progressivamente più complessi e più automatici, e nuove invenzioni creano nuovi problemi. E dunque ci viene il timore di superare un limite oltre cui non c'è più ritorno, non c'è più soluzione.
Lo abbiamo chiamato Strong AI, Intelligenza artificiale forte, Intelligence Explosion, Singolarità, AGI, ASI, e chissà come in futuro.
Se però il concetto di Superintelligenza è chiaramente definibile, la pratica è molto più difficile. Com'è fatta una superintelligenza? È un LLM potentissimo? Un GPT-6, 7, 8? È un ibrido che combina un LLM e un sistema simbolico? (un po' come AlphaGeometry di Google che univa un LLM a un sistema basato su regole logiche più dirette)
O forse è qualcos'altro?
Demis Hassabis, CEO di Google DeepMind, l'anno scorso ha dichiarato che "ci servono ancora delle grosse svolte prima di avere qualcosa che possiamo chiamare AGI.".
Mark Zuckerberg a luglio ha detto invece che "la superintelligenza è a vista d'occhio", come recita la scarna lettera su meta.com/superintelligence.
Circa un mese prima Sam Altman, CEO di OpenAI, scriveva in modo simile che "l'umanità è vicina al costruire la superintelligenza digitale".
Prevedere il futuro è notoriamente difficile: la realtà è che non c'è un consenso ben definito su quando possiamo arrivare a una "superintelligenza": se sia vicina, lontana, o se sia in generale possibile. E se anche prendessimo per buone le previsioni più ottimistiche, che entro 2-5 anni la raggiungeremo, non sappiamo come sarà fatta.
E allora che cosa comunica questa lettera? Non sarebbe come scrivere una lettera per proibire la creazione del Jurassic Park, o del farmaco che danno a Capitan America per renderlo un supereroe?

Si potrebbe rispondere che nessuno pensa che siamo quasi arrivati a far schiudere un uovo di T-Rex, mentre poco sopra riconoscevamo che in diversi credono che l'AGI sia imminente (io, di mio, sono più dell'idea che ancora non ci siamo, e che dire che ci siamo molto vicini sia in parte una mossa di marketing).
Però rimane il tema della vaghezza: la lettera è solo una vaga espressione di preoccupazione, non si capisce precisamente cosa bisognerebbe proibire: la costruzione di modelli oltre una certa dimensione? La ricerca di nuove tecniche nel Machine Learning? L'ottimizzazione dei modelli in generale?
La grande diversità di firmatari è secondo me sintomatica di un problema: se in generale trovo un valore nel creare compromessi e coalizzarsi pur avendo differenze, a un certo punto il rischio è di diluire troppo un messaggio per accontentare chiunque, e la lettera perde di mordente e di sapore.
Curiosamente, però, la lettera non si lascia diluire su un aspetto: il tempo.
2- specchietti per allodole lungotermiste

Il paraocchi sul presente è la lacuna più grossa della lettera. Né nel contesto, né nello statement si menziona in alcun modo il presente se non come ambiente in cui si prepara il futuro.
Non c'è alcun riconoscimento della situazione attuale della diffusione dei sistemi AI, dell'impatto che stanno avendo sul lavoro, sull'informazione, sulla società intera.
Le preoccupazioni che vengono citate, "l'obsolescenza economica umana il disempowerment, la perdita di libertà, di diritti civili, di dignità, di controllo, fino a rischi per la sicurezza nazionale" sono applicabili già ai sistemi AI disponibili oggi, per quanto in misura diversa da quella di un'ipotetica superintelligenza.
Mi si potrebbe dire che sto facendo benaltrismo, che parlare di problemi futuri non nega la considerazione per quelli presenti, o come mi è stato ipotizzato in un commento, che anzi parlare dei rischi futuri dia importanza alla situazione presente.
Io credo invece che il focus sul futuro sia una effettiva scelta, che non condivido.
La critica dell'occuparsi solo del futuro era stata fatta anche a una precedente lettera del 2023, quella che chiedeva lo stop di 6 mesi allo sviluppo di modelli AI più potenti di GPT-4.
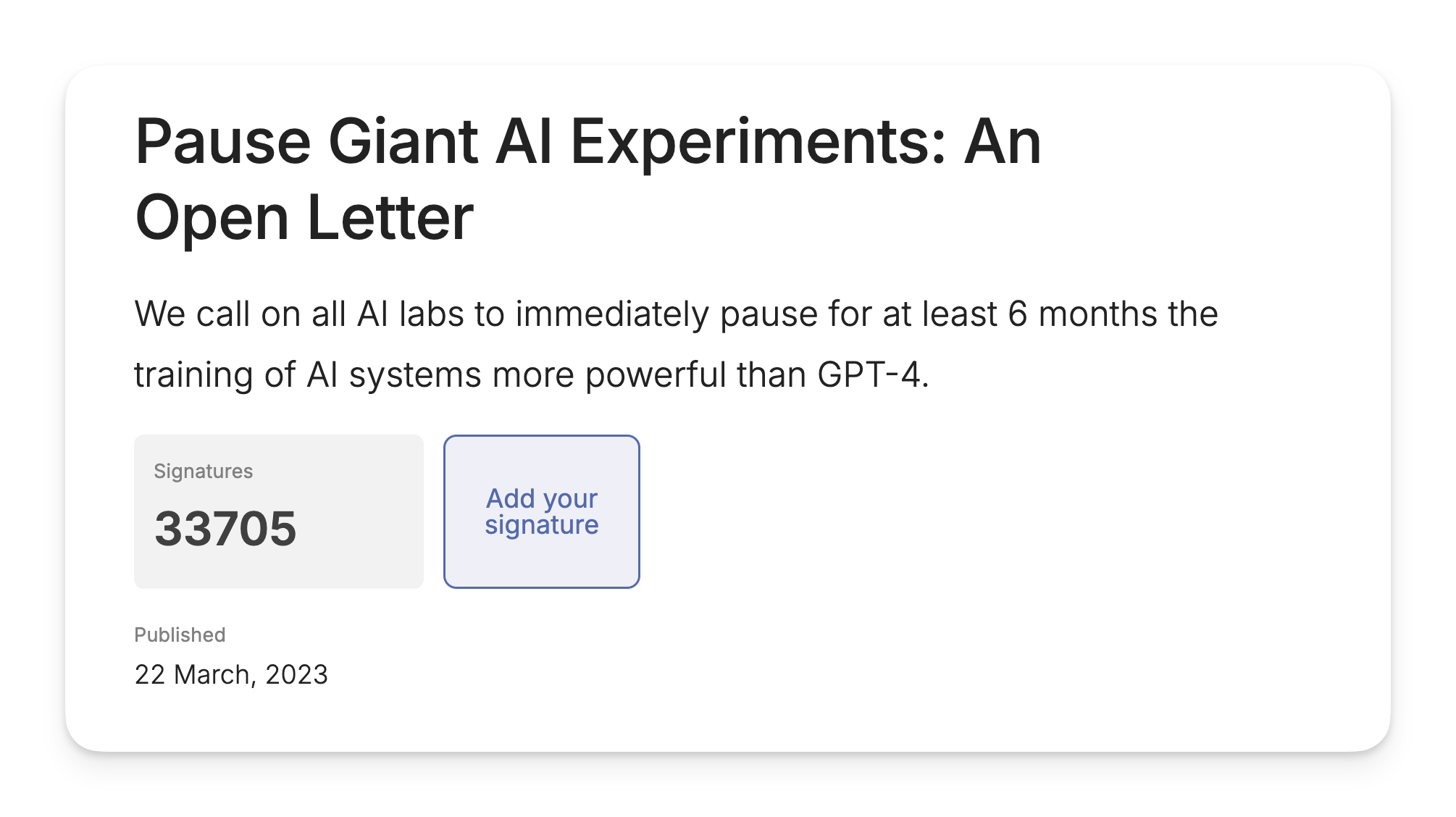
Tra i firmatari di quella lettera pubblicata il 22 marzo 2023 tra l'altro c'era anche Elon Musk, il quale proprio due settimane prima, il 9 marzo, aveva fondato la sua azienda xAI...che sviluppa modelli AI.
L'annuncio della nascita di xAI arriverà il 12 luglio 2023, nemmeno quattro mesi dopo la lettera che chiedeva sei mesi di stop. In ogni caso l'effettiva data di costituzione dell'azienda svela che non ci aveva ovviamente mai creduto.
Tornando a noi, Narayanan e Kapoor lo avevano detto bene al tempo (grassetti miei):
Concordiamo sul fatto che la disinformazione, l'impatto sul lavoro e la sicurezza sono tre dei principali rischi dell'IA.
Purtroppo, in ciascun caso, la lettera presenta un rischio speculativo e futuristico, ignorando la versione del problema che sta già danneggiando le persone.
Questo distrae dai problemi reali e rende più difficile affrontarli. La lettera ha una mentalità di contenimento analoga a quella del rischio nucleare, ma non è adatta all'IA. Fa il gioco delle aziende che cerca di regolamentare.
Anche Emily Bender, Timnit Gebru e Angelina McMillan-Major, autrici del famoso paper "Sui pericoli dei pappagalli stocastici", che avevano anticipato molto dei discorsi sui rischi degli LLM ben prima che uscisse ChatGPT, rilasciarono una dichiarazione in risposta alla lettera, che è ancora oggi validissima (grassetti miei):
Sebbene la lettera contenga una serie di raccomandazioni che condividiamo [...] queste sono messe in ombra dalla paura e dall'hype per l'IA, che indirizza il discorso verso i rischi di immaginarie "potenti menti digitali" con "intelligenza competitiva umana".
Questi rischi ipotetici sono al centro di un'ideologia pericolosa, chiamata "lungotermismo", che ignora i danni effettivi derivanti dall'impiego dei sistemi di IA oggi.
La lettera non affronta nessuno dei danni già in corso causati da questi sistemi, tra cui:
1) lo sfruttamento dei lavoratori e il furto massiccio di dati per creare prodotti che portano profitto a poche entità;
2) l'esplosione dei media sintetici nel mondo, che riproduce sistemi di oppressione e mette in pericolo il nostro ecosistema dell'informazione;
3) la concentrazione del potere nelle mani di poche persone che aggrava le disuguaglianze sociali.
La lettera del 2023 e lo statement di oggi hanno in comune la loro origine: il Future of Life Institute, che le ha pubblicate e promosse entrambe. E da qui sarà chiaro come mai il focus sul futuro è problematico.
Il Future of Life Institute è una no profit che "mira a indirizzare le tecnologie verso il beneficio della vita e l'allontanamento dei rischi di larga scala, con particolare attenzione al rischio esistenziale derivante dall'intelligenza artificiale avanzata." [1]
Con "rischio esistenziale"[2] si intende un rischio che minaccerebbe l'esistenza stessa della specie umana nella sua interezza.
La lettera del 2023 era una delle espressioni di questo timore abbastanza in voga in quel periodo, quando la successione dell'uscita di GPT-3.5 e ChatGPT, e poi GPT-4 pochi mesi dopo stavano facendo immaginare una progressione incredibilmente accelerata del futuro dell'AI.
Questa concezione di rischio esistenziale è legata a doppio filo alla corrente filosofica del lungotermismo.
Il lungotermismo, un po' comodo e un po' stupido
Il lungotermismo, o lungoterminismo (decidiamoci su come si scrive non lo so) è una corrente di pensiero secondo cui bisognerebbe considerare dal punto di vista etico le conseguenze a lunghissimo termine delle nostre azioni: la felicità delle persone future dovrebbe importare tanto quanto quella delle persone presenti.
Il lungotermismo è stato reso popolare da filosofi come William MacAskill, Peter Singer e Toby Ord, influenzati anche dalle idee di Nick Bostrom, che in Superintelligence parlava proprio del rischio esistenziale della superintelligenza AI.
Se è diventa imperativo morale occuparsi delle coscienze future, allora prevenire i rischi esistenziali diventa evidentemente una priorità. Questa filosofia nasce a sua volta dall'altruismo efficace, e lo so stiamo impilando definizioni su definizioni ma tant'è.
L'altruismo efficace è una filosofia di stampo utilitarista che propone di calcolare in modo efficace e razionale come portare il massimo beneficio con i propri sforzi.
Il movimento sociale che è scaturito dall'altruismo efficace si occupa di come scegliere gli enti di beneficenza che hanno un effetto maggiore: per esempio, se donare una stessa quantità di denaro a un certo ente potrebbe salvare 50 vite, oppure 10 vite se donata a un altro ente, sarebbe più efficace scegliere l'ente che salva 50 persone.
Questa sembra a prima vista una ovvietà, e poi sembra un'idea geniale: ma certo! È ovviamente il modo più razionale di allocare le risorse no? La taglio corta: penso che l'altruismo efficace abbia alcune intuizioni interessanti, ma ovviamente tutto dipende da come definiamo questo "massimo beneficio" e come raggiungerlo. (Per esempio, nell'altruismo efficace si sceglie di concentrarsi molto sulla beneficenza privata e poco sulla politica e sul settore pubblico...come mai?)
Nel passaggio al lungotermismo questo ideale assume forme abbastanza bizzarre: se ipotizziamo che in futuro esisteranno per esempio centinaia di miliardi di umani futuri, e dovessimo tenere conto del loro benessere con lo stesso peso degli umani che esistono oggi, ecco che ogni azione che ipoteticamente porta beneficio a questi posteri diventa giustificabile, anche se in cambio viene svantaggiato qualche migliaio di umani di oggi.
E allora ipoteticamente anche un genocidio diventa trascurabile rispetto al prevenire dei "rischi esistenziali" no?
L'assurdità di tutto ciò è il considerare come certo qualcosa che è più che ipotetico.
Se volete approfondire il lungotermismo, vi consiglio L'Utopia dei miliardari di Irene Doda, che spiega in modo chiarissimo questo ideale che si è diffuso tra i miliardari della Silicon Valley (Shop di Tlon, oppure link affiliato di Amazon).
Se questo è l'ambiente di ispirazione del Future Of Life Institute, è facile capire come mai questa lettera e la precedente guardino solo al futuro. E anche perché lo guardano senza ragionare sul presente e sui sistemi di potere che fino a oggi ci hanno portato qui.
Perché la realtà è che una lettera sullo sviluppo tecnologico ci servirebbe. Qui spezzo una lancia per certi firmatari delle lettere, che hanno sicuramente preso la possibile parte positiva –ma forse ce ne serve una diversa da questa.
Concludo evidenziando il commento lasciato da Eleonora Marocchini @narraction (seguitela sui social e sulla sua newsletter!) sul mio video:
Al di là del sensazionalismo di queste lettere che davvero non comprendo, io sono d'accordo con un punto centrale che mi sembra che comunque passi, cioè che occorre decidere a priori i limiti e le policy e non attendere di sviluppare acriticamente tecnologie di IA che poi fanno danni [...]
Concordo con te che dovremmo occuparci seriamente dei problemi di utilizzo dei modelli di Al che abbiamo già - e anche quelli andrebbero limitati e regolamentati, dovevamo farlo di più e meglio già anni fa.
L'approccio della Silicon Valley di questi decenni allo sviluppo tecnologico è stato move fast and break things –muoviti velocemente e rompi le cose– che incarnava il rifiuto dello status quo e la voglia di innovare un mondo vecchio.

E se sotto certi aspetti penso possa incarnare una legittima voglia di progresso (ne avrei di things da breakare in Italia), da un altro punto di vista ha anche incarnato la tracotanza di non volersi fermare a riflettere su rischi e conseguenze di ciò che veniva rotto. Soprattutto quando chi viene coinvolto non ha lo stesso volto da uomo occidentale ricco da Silicon Valley.
Perché come diciamo spesso, il modo in cui costruiamo la tecnologia, la scienza e dunque i loro risultati, non sono neutri. E allora manco le parole delle lettere aperte.
Cosette interessanti
👻 dovete sentire questo ricordo che è riaffiorato. una perla di Seth Everman.
🗓️ Un pezzo del filosofo Emile Torres che spiega il lungotermismo e i suoi pericoli, molto consigliato.
🔎 Cosa succede quando il tuo terapeuta condivide lo schermo per sbaglio e scopri che usa ChatGPT mentre ti fa una sessione di terapia?
🎙️ Una accurata simulazione di ogni dibattito online.
🇬🇧 Niko Omilana è andato con un travestimento a una manifestazione in UK parlando con persone che in teoria non dovevano essere razziste ma invece guarda un po' lo erano proprio.
🧑🔬 pov: fai vedere la tua nuova invenzione
🤫 Ho un sito per ricevere commenti anonimi! Mi ero stufato dei vari NGL e Tellonym, perciò me ne sono fatto uno io, senza blackjack e squillo di lusso però. (Forse potrei raccontarvelo meglio nella prossima newsletter per farne una brevina?) Se volete lasciarmi un commento, potete farlo su sussurrami e qui sotto ↓
Ancora una volta scrivere questa newsletter mi ha richiesto molto più tempo del previsto, è uscita molto più tardi di quanto avevo promesso, e soprattutto è più lunga del previsto. Vi è piaciuta così? La vorreste più corta? Più lunga? Non riesco a trovare un ordine, quindi se avete qualsiasi feedback ditemelo vi pregooo.
Ci vediamo presto, ho tante cose in mente. E grazie per la lettura 👋



Comments ()